Web scraping the Nuclear Regulatory Commission Website
Here I’ll briefly discuss how I scraped the Nuclear Regulatory Commission’s (NRC) website extracting information from each nuclear power plant. For this project I used the Scrapy, web-crawling framework written in Python, and regular expressions. The NRC page that branches out to all the nuclear power plants is: https://www.nrc.gov/info-finder/reactors/. The HTML page behind the referenced url lists all the partial url’s that are to be joined with the “master url” for further information about a specific nuclear power plant.
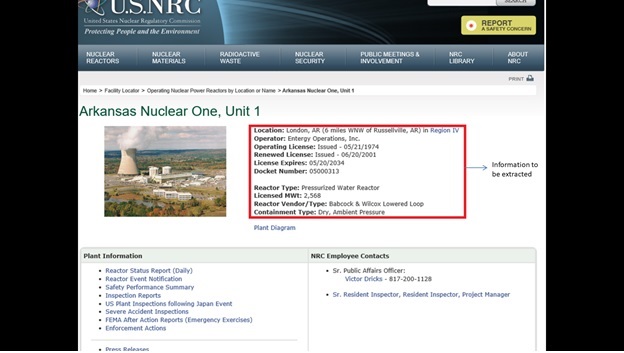
Below is an example of a particular nuclear power plant listing all the information that will be extracted.
The NRC website will be pinged for each nuclear power plant listed. Ping the NRC website enough times and you’ll have your IP address temporarily blocked (for at least a few days).
Once each url was successfully crawled regular expressions are used to extract specific information. This was not a straightforward task as each url was not consistent in how the data was stored. The final data was stored in a dictionary and then outputted as a comma separated value.